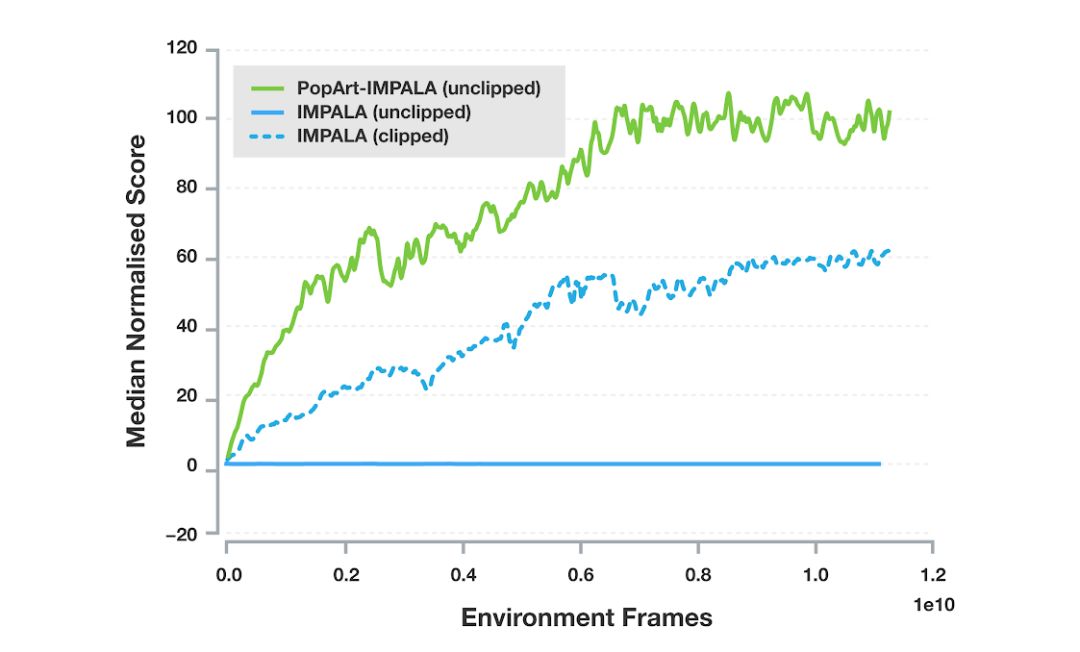
Multi-task learning—that is, allowing a single agent to learn how to complete a variety of different tasks—has been a long-term goal of artificial intelligence research. In recent years, there have been many excellent developments in this field. For example, DQN can play a variety of games including "Bricks" and "Pong" using the same algorithm. But in fact, the essence of these algorithms is to train a separate agent for each task. As artificial intelligence research begins to move closer to more complex real-world tasks, building a "multi-talented" agent—rather than multiple "expert-level" agents—will be crucial for learning to perform multiple tasks. Unfortunately, so far, this has proven to be still a major challenge. One of the reasons is that in different tasks, the reward standards used by reinforcement learning agents to judge their success are different, which causes them to fall into "reward-only theory" and focus on performing all tasks with higher rewards. For example, in the Atari game "Pong", each time the agent performs an "action", it may get the following rewards: -1, 0, or +1. In contrast, if it is the same arcade game "Miss Pac-Man", the agent may get hundreds of points for one step. Even if we set a single reward to be basically the same, as the agent gets better and better trained, the reward difference between different games will become more and more obvious due to the existence of different reward frequencies. In order to solve these problems, DeepMind developed PopArt, which can adjust the level of points in each game. Therefore, no matter how big the reward difference between different games is, the agent will treat them "equally" and judge that the rewards they bring to themselves are the same. In their latest paper Multi-task Deep Reinforcement Learning with PopArt, DeepMind uses PopArt normalization on the current state-of-the-art reinforcement learning agent, training a single agent with only a set of weights. In a set of 57 different Atari games, the performance of this agent can reach above the average level of humans. Broadly speaking, deep learning relies heavily on the update of neural network weights to make the output closer to the desired target output. The same applies to deep reinforcement learning. PopArt's working mechanism is based on estimating the average value and distribution of these goals (such as the scores in the game). Before using these statistics to update the network weights, it will first normalize them in order to form the scale and frequency of the rewards. A more robust learning experience. Later, in order to obtain a more accurate estimate-as expected score-it continues to convert the output of the network back to the original range. If you simply do this, then every update of the statistics will change the non-normalized output, including the very ideal output. This is not what we want. In order to avoid this, the solution proposed by DeepMind is that each time the statistics are updated, the network will perform a reverse update, which means that we can achieve a large-scale update of the network while keeping the output of the previous learning unchanged. . For this reason, they named this method PopArt: Preserving Outputs Precisely while Adaptively Rescaling Targets (preserving the original output while adaptively rescaling the target). Use PopArt instead of reward pruning According to the past practice, if researchers want to use reinforcement learning algorithms to prune the rewards to overcome the problem of different reward ranges, they will first set the large reward to +1 and the small reward to -1, and then Normalize the expected reward. Although this approach is easy to learn, it also changes the goal of the agent. For example, the goal of "Miss Pac-Man" is to eat beans, 10 points for each bean and 200-1600 points for ghosts. When training a reinforcement learning agent, through pruning, the agent will think that there is no difference between eating beans or eating ghosts. In addition, it is easier to eat beans. Researchers will easily train a person who only eats beans and never chases ghosts. Of the agent. As shown in the following video, after replacing reward pruning with PopArt, this agent is more "smarter", it will include chasing ghosts into its path of eating beans, and score higher: Multi-task deep reinforcement learning with PopArt In February of this year, DeepMind released a multi-task collection DMLab-30. In order to solve the problems, they also developed a highly scalable, distributed architecture-based agent IMPALA. This is currently one of the most advanced reinforcement learning agents in the world and one of the most commonly used deep reinforcement learning agents in DeepMind. In the experiment, they used PopArt for IMPALA and compared it with the baseline agent. As shown in the figure below, PopArt has greatly improved the performance of the agent. The experiment also compared the reward pruning and non-pruning situations. It can be found that the median score of the agent using PopArt in the game is higher than the median score of the human player, which is much better than the baseline performance. The unpruned baseline score is almost 0, because it cannot learn meaningful representations from the game, so it cannot handle the huge changes in the range of game rewards. 57 median performances on Atari, each row corresponds to the median performance of a single agent; the implementation is pruned, the dotted line is not pruned This is also the first time that DeepMind has seen superhuman performance of an agent in a multitasking environment, which shows that PopArt does have a certain coordination effect on the imbalance of rewards. And when we use AI systems in more complex multi-modal environments in the future, adaptive normalization methods like this will become more and more important, because agents must learn to use them when facing multiple different goals. The respective rewards are weighed as a whole. Led Wall Display,Outdoor Advertising Sign Banner,Advertising Digital Signs Banner,Outdoor Signs Banner APIO ELECTRONIC CO.,LTD , https://www.apiodisplays.com